以下针对JDK 1.8版本中的HashMap进行分析。
概述
哈希表基于Map接口的实现。此实现提供了所有可选的映射操作,并且允许键为null,值也为null。HashMap 除了不支持同步操作以及支持null的键值外,其功能大致等同于 Hashtable。这个类不保证元素的顺序,并且也不保证随着时间的推移,元素的顺序不会改变。
假设散列函数使得元素在哈希桶中分布均匀,那么这个实现对于 put 和 get 等操作提供了常数时间的性能。
对于一个 HashMap 的实例,有两个因子影响着其性能:初始容量和负载因子。容量就是哈希表中哈希桶的个数,初始容量就是哈希表被初次创建时的容量大小。负载因子是在进行自动扩容之前衡量哈希表存储键值对的一个指标。当哈希表中的键值对超过capacity * loadfactor时,就会进行 resize 的操作。
作为一般规则,默认负载因子(0.75)在时间和空间成本之间提供了良好的折衷。负载因子越大,空间开销越小,但是查找的开销变大了。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在非同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出ConcurrentModificationException异常。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。
源码分析
主要字段
|
|
从上面我们可以得知,HashMap中指定的哈希桶数组table.length必须是2的幂次方,这与常规性的把哈希桶数组设计为素数不一样。指定为2的幂次方主要是在两方面做优化:
- 扩容:扩容的时候,哈希桶扩大为当前的两倍,因此只需要进行左移操作
- 取模:由于哈希桶的个数为2的幂次,因此可以用&操作来替代耗时的模运算,
n % table.length -> n & (table.length - 1)
哈希函数
|
|
key 的哈希值通过它自身hashCode的高十六位与低十六位进行亦或得到。这么做得原因是因为,由于哈希表的大小固定为 2 的幂次方,那么某个 key 的 hashCode 值大于 table.length,其高位就不会参与到 hash 的计算(对于某个 key 其所在的桶的位置的计算为 hash & (table.length - 1))。因此通过hashCode()的高16位异或低16位实现的:(h = key.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,保证了高位 Bits 也能参与到 Hash 的计算。
tableSizeFor函数
|
|
根据注释可以知道,这个函数返回大于或等于cap的最小二的整数次幂的值。比如对于3,返回4;对于10,返回16。详解如下:
假设对于n(32位数)其二进制为 01xx…xx,
n >>> 1,进行无符号右移一位, 001xx..xx,位或得 011xx..xx
n >>> 2,进行无符号右移两位, 00011xx..xx,位或得 01111xx..xx
依此类推,无符号右移四位再进行位或将得到8个1,无符号右移八位再进行位或将得到16个1,无符号右移十六位再进行位或将得到32个1。根据这个我们可以知道进行这么多次无符号右移及位或操作,那么可让数n的二进制位最高位为1的后面的二进制位全部变成1。此时进行 +1 操作,即可得到最小二的整数次幂的值。(《高效程序的奥秘》第3章——2的幂界方 有对此进行进一步讨论,可自行查看)
回到上面的程序,之所以在开头先进行一次 -1 操作,是为了防止传入的cap本身就是二的幂次方,此时得到的就是下一个二的幂次方了,比如传入4,那么在不进行 -1 的情况下,将得到8。
构造函数
|
|
对于上面的构造器,我们需要注意的是this.threshold = tableSizeFor(initialCapacity);这边的 threshold 为 2的幂次方,而不是capacity * load factor,当然此处并非是错误,因为此时 table 并没有真正的被初始化,初始化动作被延迟到了putVal()当中,所以 threshold 会被重新计算。
查询
|
|
存储
|
|
扩容
|
|
因为哈希表使用2次幂的拓展(指长度拓展为原来的2倍),所以在扩容的时候,元素的位置要么在原位置,要么在原位置再移动2次幂的位置。为什么是这么一个规律呢?我们假设 n 为 table 的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。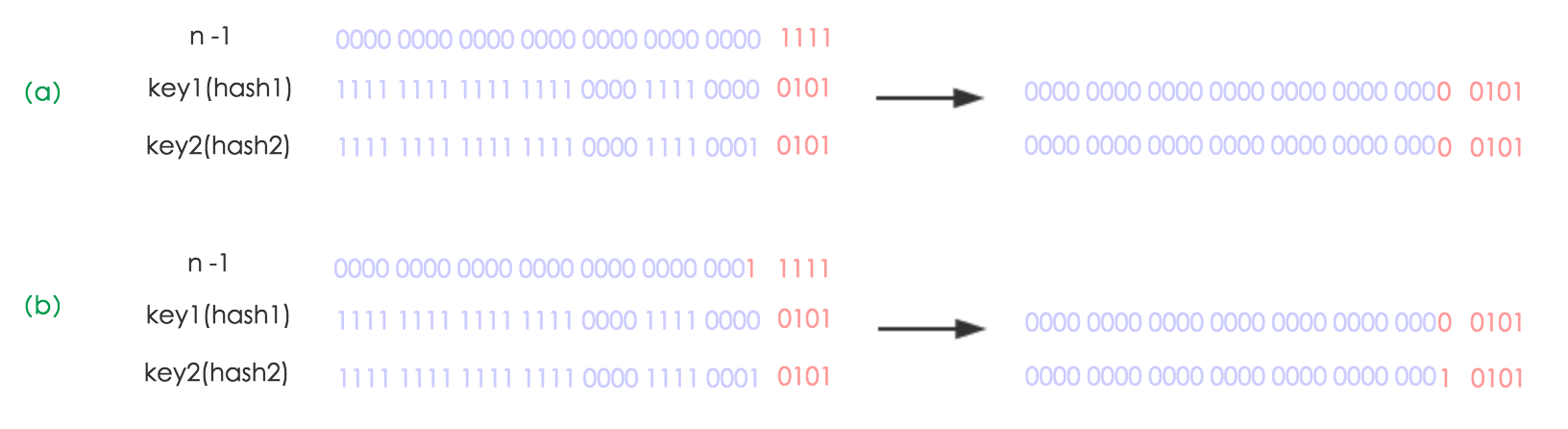
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
因此,我们在扩容的时候,只需要看看原来的hash值新增的那个 bit 是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图:
删除
|
|
问题
- 对于
new HashMap(18),那么哈希桶数组的大小是多少 - HashMap 要求哈希桶数组的长度是2的幂次方,这么设计的目的是为什么
- HashMap 何时对哈希桶数组开辟内存
- 哈希函数是如何设计的,这么设计的意图是什么
- HashMap 扩容的过程,扩容时候对 rehash 进行了什么优化